Prompt compression reduces the number of input tokens sent to an LLM – often by 3–20× on long contexts – by using a small model to identify and remove low-information words while preserving the prompt’s meaning.
On long RAG and multi-document workloads, where input tokens dominate the bill, it’s one of the highest-yield optimizations going. This post explains how LLMLingua-2 works and where it’s safe to apply.
The insight: not all tokens carry information
Natural-language prompts are padded. Articles, filler words, repeated phrasing, and verbose connective tissue all eat tokens without changing what the model understands. A human can read a heavily abbreviated note and still reconstruct the meaning – and large models can too. Prompt compression takes advantage of that: it strips the low-information tokens, keeps the ones carrying the meaning, and sends a denser prompt that costs far less but produces nearly the same output.
On a 4,000-token RAG context, 3–20× compression means sending 1,300 tokens – or 200 – instead of 4,000, at under 2% quality loss. Input tokens are most of the bill on RAG workloads, which is exactly where compression bites hardest.
How LLMLingua-2 works
LLMLingua-2 (and the related RECOMP approach) uses a small, fast token-classification model trained to score how important each token is. The classifier runs over the prompt and tags each token keep-or-drop; the low-importance ones are dropped, and the compressed prompt goes to the main model. The classifier is small enough to run on CPU in 5–40 milliseconds for a typical prompt – cheap next to the LLM call it’s about to shrink.
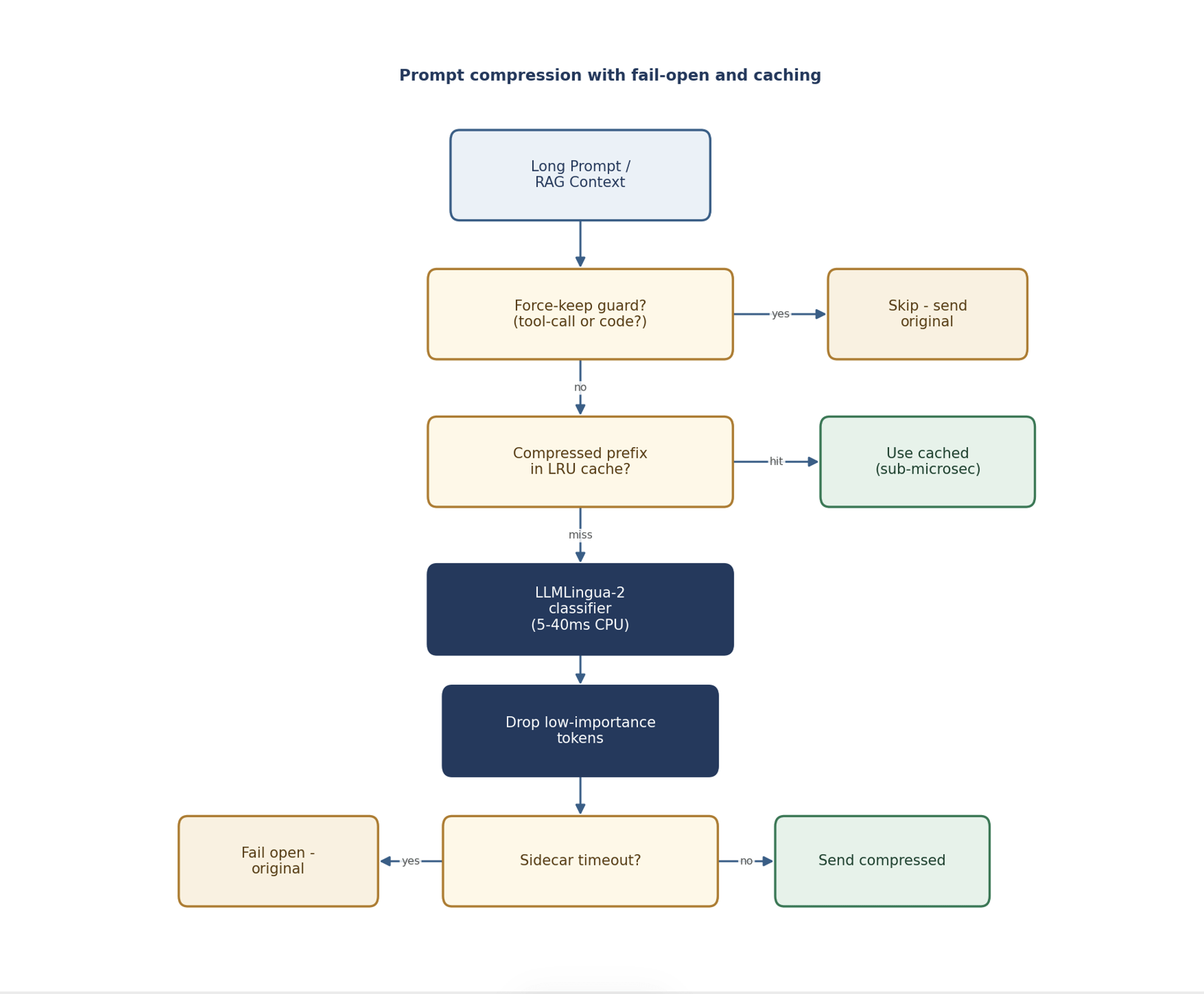
Two safety mechanisms that make it production-grade
Force-keep guards
Some prompts must never be compressed, because compression would wreck their structure. Tool-calling requests contain JSON whose syntax has to stay intact – drop the wrong token and it won’t parse. Code-heavy prompts depend on exact indentation and symbols. A production compressor spots these (heuristically) and skips compression for them entirely, putting correctness ahead of savings. Compressing a tool call to save a few tokens and breaking the call is a net loss; force-keep guards prevent it.
Fail-open by design
The compressor runs as a sidecar with a timeout (commonly around 200ms). If it’s slow or down, the system falls back to sending the original, uncompressed prompt instead of blocking the request. You lose the savings on that one request, but never the request itself. Compression is an optimization, not a dependency – it should never be able to take down the request path.
The compressed-prefix cache
Most production traffic shares a stable prefix – the same system prompt, the same RAG template, the same instructions. Compressing that prefix every single time would waste the classifier’s effort. A compressed-prefix LRU cache stores the compressed form of common prefixes, so the 90%+ of traffic that reuses a prefix gets a sub-microsecond cache lookup instead of a fresh compression pass. The expensive classification happens once per unique prefix, then gets reused.
Where to use it – and where not to
- Use it on: long RAG contexts, multi-document synthesis, large retrieved passages, verbose system prompts – anywhere input tokens are big and a bit padded.
- Be cautious on: short prompts (little to compress, the overhead isn’t worth it), highly precise instructions where every word matters, and anything where the exact wording is the point.
- Never on: tool-call JSON and code, unless your compressor has solid force-keep detection.
As with every layer in the stack, run a drift sampler so a slice of traffic skips compression and you can watch the quality delta continuously.
🔗 Internal link: Primary CTA: /platform/cost-optimization/. Link up to Post 9 (pillar). Link ‘RAG context’ to Post 12 (RAG re-ranking) – the two pair naturally. Link ‘tool-calling requests’ to Post 18 (MCP gateway).
How DeepintShield approaches this
DeepintShield applies prompt compression with the production safeguards this post describes: force-keep guards skip compression for tool-call JSON and code, a sidecar timeout fails open to the original prompt instead of blocking, and a compressed-prefix cache reuses common prefixes so the classifier runs once per unique prefix. A drift sampler lets you watch the quality delta as you roll it out. For teams running long RAG or multi-document workloads where input tokens dominate the bill, DeepintShield is one way to apply compression safely instead of risking broken tool calls.





