The OWASP Agentic ASI Top 10 (2026) is a framework that lists the ten most critical security risks specific to agentic AI systems.
The older OWASP LLM Top 10 covers risks to language models; the Agentic ASI list covers the brand-new attack surface that opens up once you give those models tools, memory, and the freedom to act. This walkthrough goes through all ten, with a practical fix for each.
Why a separate framework for agents
The OWASP LLM Top 10 (2025) did a great job cataloging risks to language models – prompt injection, sensitive-info disclosure, insecure output handling, and so on. But it was written for a world where the model mostly answered questions. Agents changed the threat model. Once an agent can call tools, write to memory, and act on its own, it has an attack surface the LLM Top 10 never saw coming.
The Agentic ASI Top 10 fills that gap. ASI stands for Agentic Systems and Infrastructure, and the list reflects how attacks on agents actually play out in production – not theory, but the categories researchers and red teams keep running into.
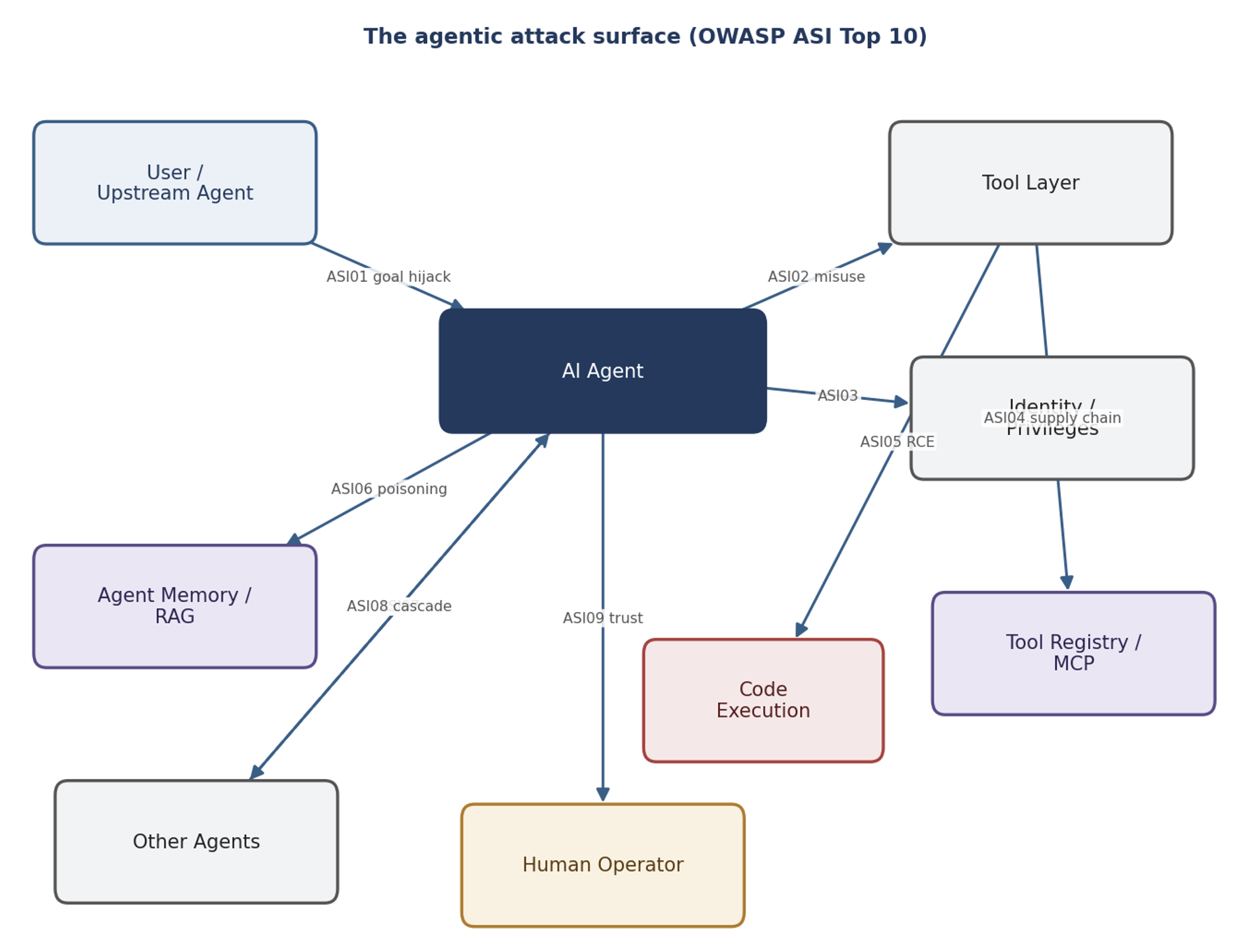
ASI01 – Goal hijack
An attacker hijacks the agent’s objective so it chases their goal instead of the user’s. This usually shows up as prompt injection hidden in retrieved content – a document the agent reads contains instructions that quietly override its task. The agent thinks it’s still helping the user; it’s actually running the attacker’s plan.
Mitigation: input-stage guardrails that catch prompt injection, plus a policy engine that blocks any tool call outside the agent’s declared capabilities – so even a hijacked agent can’t break out of its permission envelope.
ASI02 – Tool misuse
The agent uses a legitimate tool in a harmful way it was never meant for. A file-read tool gets pointed at /etc/passwd. A database tool gets a query with a destructive side effect. The tool is allowed; the specific use is the attack.
Mitigation: tool tiering with per-tool policies – allowed domains, allowed identities, restricted actions – plus a tool integrity engine that flags when a call’s arguments stray from the tool’s normal behavior.
🔗 Internal link: Link ‘tool integrity engine’ to Post 4 (Tool Integrity Engine).
ASI03 – Identity and privilege abuse
The agent runs with more privilege than the task needs, or an attacker bumps up its effective identity. A support agent that can read any customer’s records – not just the one in the current ticket – is a standing ASI03 risk: one injection away from mass data access.
Mitigation: ABAC operands that tie decisions to agent risk level, data class, and namespace; per-virtual-key budgets and scopes; least-privilege identity resolution.
ASI04 – Supply chain
A tool, model, or dependency in the agent’s supply chain gets compromised. The classic move: an MCP tool is silently re-described – same name and interface, but its description (which the model reads) now carries malicious instructions. Or a typosquatted tool poses as a legitimate one.
Mitigation: this is where AIBOM and tool pinning earn their keep. Pin each tool to its contract fingerprint, trip a fingerprint-drift signal the moment the contract changes, and export a CycloneDX AI Bill of Materials so you have an auditable inventory of every tool and its verified state.
🔗 Internal link: Link ‘AIBOM and tool pinning’ to Post 3 (AIBOM Explained). Link ‘fingerprint-drift’ to Post 8.
ASI05 – Unexpected remote code execution
The agent gets tricked into running code it shouldn’t – through a code-execution tool, a sandbox escape, or a payload that reaches an interpreter. Agents that can run code are especially exposed.
Mitigation: code-execution detection in the guardrail layer, a sandbox verdict that boxes in risky payloads, and a hard wall between the agent’s reasoning context and any execution environment.
ASI06 – Memory and context poisoning
An attacker plants false information in the agent’s memory or retrieval corpus so it resurfaces later as trusted context. The poison goes in once and keeps coming back, so the damage compounds over time. Think of it as the agentic version of stored XSS.
Mitigation: RAG-stage policy evaluation that trust-scores every retrieved chunk, quarantine for low-trust sources, and integrity checks on memory-write tools so poisoned writes get caught the moment they’re inserted.
🔗 Internal link: Link ‘RAG-stage policy evaluation’ to Post 24 (RAG Security).
ASI07 – Insecure inter-agent communication
In multi-agent systems, one agent’s output becomes another’s input. If that channel isn’t secured, a compromised agent can inject instructions into its peers – and the trust agents place in each other becomes the attack vector.
Mitigation: MCP gateway policies checked on both inbound and outbound tool calls, per-tool allowed-identities so an agent only accepts calls from authorized peers, and treating inter-agent messages with the same suspicion as user input.
ASI08 – Cascading failures
A failure or compromise in one agent or tool spreads through the system, getting bigger as it goes. One bad verdict bleeds into the decisions that depend on it; one overwhelmed tool triggers retries that overwhelm the next.
Mitigation: per-tool fail postures (low-risk reads fail open, high-risk writes fail closed), decision boundaries that stop verdicts bleeding across contexts, and circuit breakers on tool calls.
ASI09 – Human-trust exploitation
The agent takes advantage of the human operator’s trust – dressing up a harmful action as routine, or burying a consequential step inside a long, plausible-looking sequence so the human waves it through.
Mitigation: an approval queue that shows the full context of each flagged action – inputs, outputs, the policy that triggered it, the principal chain – so humans review with the whole picture instead of rubber-stamping.
ASI10 – Rogue agents
An agent operates completely outside its authorized scope – an unregistered agent making decisions through your infrastructure, or a registered one that’s drifted far from its intended behavior. You can’t govern what you haven’t discovered.
Mitigation: agent discovery that surfaces every agent touching the platform – including unregistered ones – and rollout controls that keep unknown agents in shadow mode until a human reviews and approves them.
🔗 Internal link: Link ‘agent discovery’ to Post 6 (Shadow Agents).
The ten ASI categories aren’t independent – one sophisticated attack often chains several together. A supply-chain compromise (ASI04) enables tool misuse (ASI02), which lands a goal hijack (ASI01), kept alive through memory poisoning (ASI06). Defending against the list means defending the whole agentic execution path, not bolting on ten separate point solutions.
The ten ASI categories aren’t independent – a single sophisticated attack often chains several. A supply-chain compromise (ASI04) enables tool misuse (ASI02), which achieves goal hijack (ASI01), persisted through memory poisoning (ASI06). Defending against the list means defending the whole agentic execution path, not ten separate point solutions.
That’s the architectural case for a converged agentic-security control plane: one inline enforcement point that sees every tool call, every retrieved chunk, every memory write, and every inter-agent message – and applies policy consistently across all of them, with a single audit log proving what happened.
🔗 Internal link: Primary CTA: /platform/agentic-security/ and /compliance/. Link ‘converged agentic-security control plane’ to Post 1 (pillar). This post is a strong featured-snippet target for the ASI list – keep the ten H2 headings clean.
How DeepintShield approaches this
DeepintShield maps its controls straight onto the Agentic ASI Top 10: inline policy enforcement and capability limits cover goal hijack and tool misuse; ABAC and least-privilege identity cover excessive agency; a Tool Integrity Engine and AIBOM cover supply-chain compromise; RAG-stage trust-scoring covers memory and context poisoning; and output scanning on inter-agent messages covers cascading failures. Instead of ten separate point fixes, it secures the whole agentic execution path through one control plane. If you’re using the ASI list as a checklist, DeepintShield is one way to cover the categories coherently rather than buying a different tool for each.





