RAG re-ranking uses a cross-encoder model to score each retrieved chunk against the user’s actual question, then drops the low-scoring chunks before they reach the LLM – typically cutting context size 40–70% with no loss in answer quality.
It fixes the core inefficiency of naive retrieval: stuffing the model with chunks that matched on vector similarity but don’t actually help answer the question.
Why retrieval over-fetches
Standard RAG retrieves chunks by embedding similarity – it grabs the passages whose vectors sit closest to the query vector. That’s fast and approximate, which is the whole point. But approximate means noisy: plenty of retrieved chunks are topically related yet useless for the specific question. Teams compensate by pulling more chunks (top-20 instead of top-5) to be sure the answer is in there somewhere. The result is a bloated context – most of it unhelpful – that you pay for on every call, and that can actually hurt answer quality by burying the relevant passage in noise.
Embedding similarity is good at ‘related.’ It’s mediocre at ‘actually answers the question.’ Re-ranking adds that second judgment, so you can retrieve broadly and then keep only what helps.
Bi-encoders vs cross-encoders
Retrieval and re-ranking use different models because of a speed-accuracy tradeoff. Retrieval uses a bi-encoder: it embeds the query and the documents separately, so document embeddings can be precomputed and searched fast. That’s what lets vector search scale to millions of chunks – but encoding query and document independently throws away some of the interaction between them.
A cross-encoder encodes the query and a chunk together, so the model can attend to their interaction directly. That’s far more accurate at judging relevance – but too slow to run over your whole corpus. The winning pattern: a bi-encoder retrieves broadly (fast, approximate), then a cross-encoder re-ranks the retrieved set (slow, accurate, but only over the handful of candidates). A model like bge-reranker-v2-m3 is purpose-built for this re-ranking step.
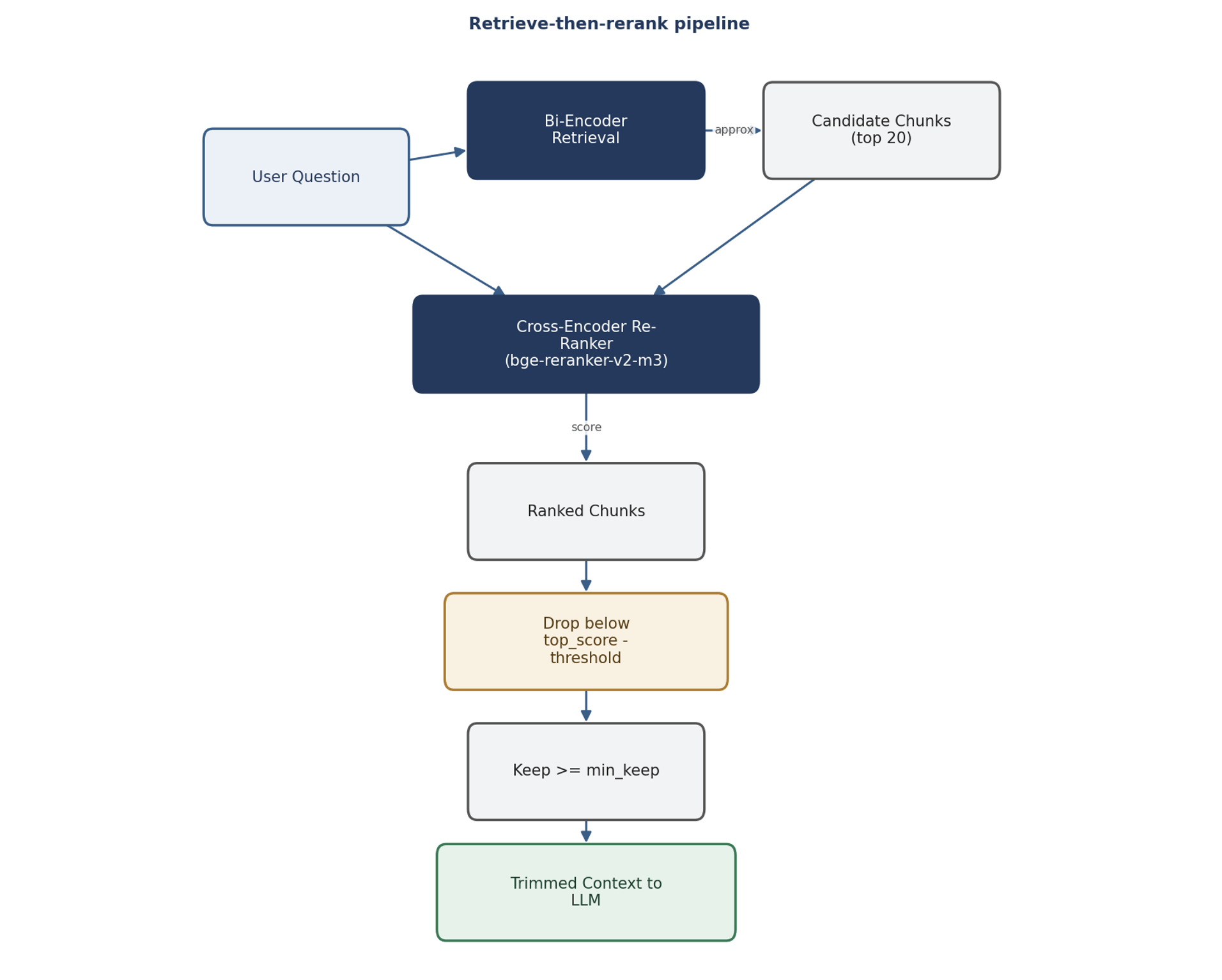
How the trimming decision works
After the cross-encoder scores each candidate chunk, the system trims by relative score. A relative threshold beats a fixed cutoff: keep the chunks scoring within some delta of the top chunk, drop the rest. A min-keep floor makes sure you never trim below a safe minimum (you always send at least N chunks), and a max-chunks cap bounds the top end. The effect is adaptive – a question with one clearly-relevant passage trims hard; a question that needs several passages keeps more.
Detecting RAG-shaped prompts
For re-ranking to kick in automatically, the system has to recognize when a prompt contains retrieved context. Production implementations spot RAG structure through common markers – XML-style tags like <context>, <doc>, <chunk>, <document>, or <passage>, and markdown patterns like “Document N:”, “## Source N”, or bracketed citations. When these show up, the re-ranker engages; when they don’t, the prompt passes through untouched.
The score cache
Re-ranking the same (query, chunks) pair over and over is wasteful, and on stable corpora it happens a lot. A persistent score cache (commonly hundreds of thousands of entries with a 24-hour TTL) stores prior relevance scores, so repeat lookups are sub-microsecond. With a generous failure budget (re-ranking can take longer than compression before falling back), the same fail-open contract applies: if the re-ranker is slow or down, the full retrieved set passes through instead of blocking the request.
Re-ranking pairs with compression
Re-ranking and prompt compression hit context cost from two different angles and pair well. Re-ranking removes whole chunks that don’t help; compression then squeezes the ones that remain. Run re-ranking first (drop the irrelevant chunks), then compression (densify what’s left), and the combined context reduction is bigger than either alone – often taking a 20-chunk, 4,000-token retrieval down to a handful of dense, relevant passages.
🔗 Internal link: Link ‘prompt compression’ to Post 11. Link ‘RAG structure’ / RAG security angle to Post 24 (RAG Security). Link up to Post 9 (pillar).
🔗 Internal link: Primary CTA: /platform/cost-optimization/.
How DeepintShield approaches this
DeepintShield runs RAG re-ranking as part of its cost stack: a cross-encoder scores each retrieved chunk against the question and trims below a relative threshold with a min-keep floor, shrinking context size while preserving answer quality, with a score cache and fail-open behavior for production safety. Because the same retrieved chunks are also checked for trust at the RAG guardrail stage, re-ranking for cost and scoring for safety happen in one go. For teams whose RAG context is bloated with low-relevance chunks, DeepintShield is one way to trim it for cost and clean it for safety in a single pass.





