Reasoning-effort throttling sets the reasoning budget of a reasoning-capable model to match the difficulty of the task – saving 30–70% on reasoning-token spend by not running maximum effort on work that doesn’t need it.
It fixes a specific, expensive default: most applications hardcode reasoning models to their highest effort tier and pay for deep deliberation on tasks that need none of it.
The hidden cost of reasoning models
Reasoning models – OpenAI’s o-series, Anthropic’s extended thinking, Gemini’s Deep Think – generate internal reasoning tokens before they answer. Those reasoning tokens get billed, and they can dwarf the visible output. On a hard math or planning problem, that deliberation is worth paying for. On a simple classification (“is this email spam: yes or no”), running the model at maximum reasoning effort produces a wall of reasoning tokens to answer a question that needed none. The model still gets it right – you just paid 10× more than necessary for the privilege.
A reasoning model cranked to maximum effort on a classification task is a Ferrari idling in traffic. Throttling matches the effort to the task – full power when the road opens up, idling when it doesn’t.
How throttling works
Throttling spots reasoning-capable models and rewrites the reasoning parameters per request – the effort level or the maximum reasoning tokens – based on a task-type label. The label tells the system how hard the task is, and a mapping turns that into the right effort tier.
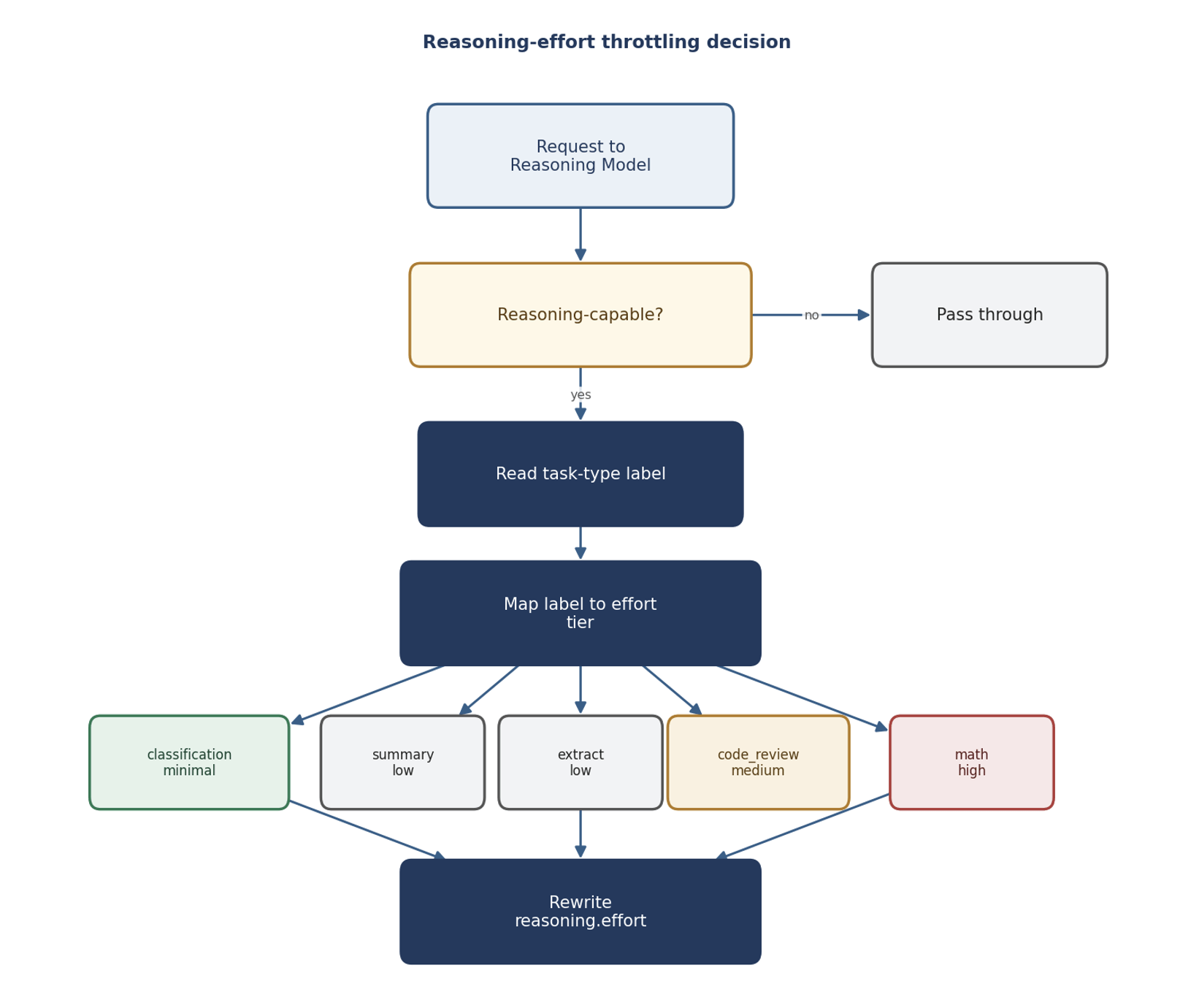
Where the task label comes from
The task-type label can arrive through a few channels, in order of precedence: an explicit request header, an SDK metadata field, or a governance metadata key. If none is supplied, a workspace default kicks in. This layering lets application teams label individual requests right where they know the task type, while still leaving a sensible org-wide fallback for traffic that isn’t labeled.
Common labels map to effort tiers like this: classification and extraction need minimal reasoning; summarization is low; code review is medium; genuine math, planning, and multi-step reasoning get high or maximum. The mapping is configurable – tune it to your own quality bar per task type.
The safety net: a drift sampler on quality
Throttling is the layer where quality worries are most legitimate – dialing down reasoning could hurt outputs if a task turns out harder than its label suggests. The fix is the same drift sampler used across the cost stack: a configurable slice of traffic runs at the caller’s original (un-throttled) effort, and the two are compared. If a task type’s throttled outputs slip, the sampler surfaces it and you bump that label’s tier up. You throttle with evidence, not hope.
Why this is increasingly important
As reasoning models become the default for more workloads, the share of LLM spend going to reasoning tokens keeps climbing. Teams that adopt reasoning models without throttling often watch bills jump severalfold, because every request – trivial or hard – now runs deep deliberation. Throttling restores proportionality: you pay for reasoning where it helps and stop paying for it where it doesn’t. On a mixed workload, 30–70% off the reasoning portion of the bill is typical, with no quality loss on the tasks that were over-provisioned.
🔗 Internal link: Primary CTA: /platform/cost-optimization/. Link up to Post 9 (pillar). Link ‘cascade routing’ (related cheap-vs-expensive idea) to Post 15.
How DeepintShield approaches this
DeepintShield does reasoning-effort throttling exactly as described: it detects reasoning-capable models and rewrites the reasoning budget per request based on a task-type label (minimal for classification, high for genuine math and planning), with a workspace default for unlabeled traffic and a drift sampler to confirm quality. Paired with its virtual-key budgets, throttling makes each request appropriately cheap while the caps bound the total. For teams whose reasoning-model bill has jumped severalfold, DeepintShield is one way to restore proportionality without losing quality on the tasks that were over-provisioned.





