Semantic caching serves a stored LLM response when a new request is similar in meaning to a previous one – not just byte-identical – by comparing embedding vectors rather than exact text.
It’s the single highest-leverage cost optimization for most production workloads, because real users ask the same things in different words – and an exact-match cache misses all of it.
Why exact-match caching isn’t enough
A traditional cache keys on the exact request. Ask “what’s your refund policy?” and the answer gets cached. But the next user asks “how do I get my money back?” – same intent, different words – and an exact-match cache treats it as brand new and pays for another LLM call. In real traffic, the same underlying question shows up in dozens of phrasings. Exact-match caching catches only the literal repeats and misses the semantic ones, which are the majority.
Users don’t repeat strings. They repeat intent. A cache that only matches strings leaves most of the savings sitting in your traffic.
Dual-mode: hash first, then similarity
The most efficient design runs two modes in sequence. First, a fast exact-hash check (using a cheap hash like xxhash) catches literal repeats in microseconds – no embedding needed. Only on an exact-hash miss does the system compute an embedding and go looking for semantically similar past requests. That keeps the common case – literal repeats – nearly free, and saves the pricier similarity search for when it’s actually needed.
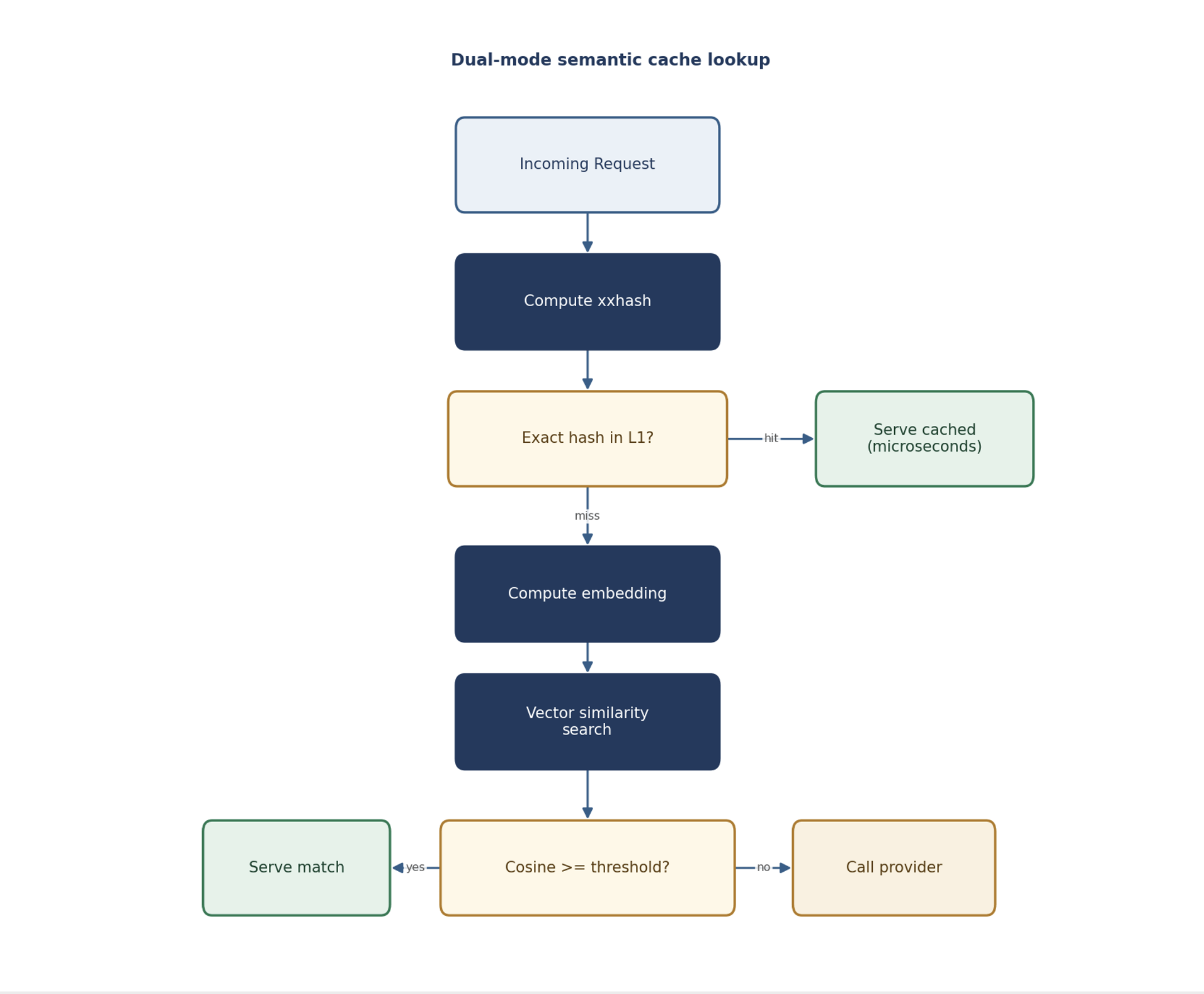
The similarity threshold is the key knob
Semantic caching lives or dies by its cosine-similarity threshold – how close two requests have to be to count as a match. Set it too low and you serve a cached answer to a question that’s only loosely related, which means wrong responses. Set it too high and you miss legitimate matches and lose savings. A common default sits around 0.8, but the right value depends on your domain: factual lookups can handle a higher threshold (the answers are stable), while nuanced or personalized queries need a stricter one. Make the threshold tunable per request via headers, so different endpoints can run different policies.
Per-tenant isolation: the safety requirement
The one thing a semantic cache must never do is hand one tenant’s response to another. If two customers ask similar questions, customer B must never get a cached answer generated for customer A – that answer might contain A’s data. Correct implementations scope every cache entry by virtual key (and therefore by tenant and workspace), so similarity search only ever matches within the same isolation boundary. Cross-tenant cache leakage is treated as a critical defect, not a tuning knob.
🔗 Internal link: Link ‘virtual key’ to Post 22 (Virtual API Keys). Link ‘tenant and workspace’ to Post 21 (Multi-Tenant LLM Platforms).
Cache key customization
Real workloads need control over what counts as a cache match. Handy customizations: leave the system prompt out of the key (so a system-prompt tweak doesn’t blow away the whole cache), scope by model and provider (so a GPT-4o answer isn’t served to a Claude request), and skip the cache when conversation history gets long (those contexts are usually too specific to reuse). Per-request headers should let callers override TTL, threshold, and cache behavior on individual requests.
What semantic caching can and can’t do
It shines on workloads with repeated intent: customer support, FAQ, documentation Q&A, internal knowledge bases. It’s much less useful where every request is genuinely unique – one-off creative generation, highly personalized outputs, or requests dominated by unique context. Knowing which kind of workload you have tells you whether semantic caching is your biggest lever or a minor one. For most enterprise deployments, it’s the biggest.
🔗 Internal link: Primary CTA: /platform/cost-optimization/. Link up to Post 9 (pillar). Link ‘provider’s prompt cache’ concepts to Post 14.
How DeepintShield approaches this
DeepintShield’s semantic cache uses exactly the dual-mode design described here: a fast exact-hash check first, then embedding-based similarity search on a miss, with a cosine threshold you can tune per request. Crucially, every cache entry is scoped to a virtual key – and therefore a tenant and workspace – so similarity search only ever matches within the same isolation boundary, which rules out cross-tenant leakage. For teams whose workloads have repeated intent (support, FAQ, documentation Q&A), DeepintShield is one way to capture the semantic-cache savings without the leakage risk.





